Lesson11 字典(HashMap)专题
目录
-
HashMap的基本概念
-
例题讲解和举一反三
-
课后练习
1. HashMap的基本概念
1.1 Java 中的 HashMap
HashMap 是 Java 中的一个非常常用的数据结构,用来存储键值对(Key-Value)的映射。它是基于哈希表实现的,因此能提供高效的插入、删除和查找操作。HashMap 允许存储 null 键和 null 值,但它是非同步的,即多个线程同时操作时可能会导致数据不一致。
1.2 HashMap 的基本特性:
- 无序存储:
HashMap 中的键值对是无序的,插入顺序不被保证。
- 允许
null 键和 null 值:HashMap 允许一个 null 键和多个 null 值。
1.3 HashMap 的常用方法:
put(K key, V value):将指定的键值对插入到映射中。如果键已经存在,则更新其对应的值。get(Object key):根据键获取对应的值,如果键不存在则返回 null。remove(Object key):根据键删除对应的键值对。containsKey(Object key):检查 HashMap 中是否存在指定的键。containsValue(Object value):检查 HashMap 中是否存在指定的值。size():返回 HashMap 中键值对的数量。isEmpty():检查 HashMap 是否为空。keySet():返回 HashMap 中所有键的集合。values():返回 HashMap 中所有值的集合。entrySet():返回 HashMap 中所有键值对的集合。
1.4 示例代码
| Java |
|---|
| import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
// 创建一个 HashMap 实例
HashMap<String, Integer> map = new HashMap<>();
// 添加键值对
map.put("Apple", 10);
map.put("Banana", 20);
map.put("Orange", 30);
// 获取键值对
System.out.println("Apple: " + map.get("Apple")); // 输出: Apple: 10
// 判断是否包含键或值
System.out.println("Contains key 'Banana': " + map.containsKey("Banana")); // 输出: true
System.out.println("Contains value 30: " + map.containsValue(30)); // 输出: true
// 删除键值对
map.remove("Banana");
System.out.println("After removal of 'Banana': " + map);
// 获取 HashMap 的大小
System.out.println("Size of map: " + map.size());
}
}
|
运行结果:
| Text Only |
|---|
| Apple: 10
Contains key 'Banana': true
Contains value 30: true
After removal of 'Banana': {Apple=10, Orange=30}
Size of map: 2
|
1.5. 遍历HashMap
Java的HashMap提供了多种遍历方式:
1.5.1 遍历键
可以使用keySet()方法获取所有键,并遍历它们:
| Java |
|---|
| for (KeyType key : map.keySet()) {
System.out.println(key);
}
|
1.5.2 遍历值
可以使用values()方法获取所有值并遍历它们:
| Java |
|---|
| for (ValueType value : map.values()) {
System.out.println(value);
}
|
1.5.3 遍历键值对
可以使用entrySet()方法遍历所有键值对:
| Java |
|---|
| for (Map.Entry<KeyType, ValueType> entry : map.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
|
示例代码
| Java |
|---|
| import java.util.HashMap;
import java.util.Map;
public class HashMapTraversalExample {
public static void main(String[] args) {
// 创建并初始化一个 HashMap
HashMap<String, Integer> map = new HashMap<>();
map.put("Apple", 10);
map.put("Banana", 20);
map.put("Orange", 30);
map.put("Grapes", 40);
// 1. 遍历键 (key) 集合
System.out.println("遍历键集合 (Keys):");
for (String key : map.keySet()) {
System.out.println("Key: " + key);
}
// 2. 遍历值 (value) 集合
System.out.println("\n遍历值集合 (Values):");
for (Integer value : map.values()) {
System.out.println("Value: " + value);
}
// 3. 遍历键值对 (key-value pairs)
System.out.println("\n遍历键值对 (Key-Value Pairs):");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
}
}
|
1.6 哈希表的原理和性质
1.6.1 基本结构
-
键值对(Key-Value Pair):
- 在
HashMap 中,每个元素都是一个键值对,包含一个唯一的键和与之关联的值。
- 键是唯一的,不能重复,而值可以重复。
-
桶(Bucket):
HashMap 使用数组来存储桶,数组的每个元素称为一个桶。每个桶可以存储一个或多个键值对。- 桶的数量由
HashMap 的容量(capacity)决定。
-
哈希函数:
1.6.2 工作原理
-
插入操作:
- 计算键的哈希值,并根据哈希值计算桶的索引。
- 如果对应桶为空,直接插入键值对。
- 如果桶不为空,则检查链表中是否存在相同的键,若存在,则更新值;若不存在,则在链表末尾添加新键值对。
-
查找操作:
- 根据键计算桶的索引。
- 检查桶中是否有键值对,如果有,通过遍历链表查找对应的值。
-
删除操作:
- 根据键计算桶的索引。
- 检查桶中是否有键值对,如果有,通过遍历链表找到并删除对应的键值对。
1.6.3 哈希函数详解
HashMap 通过 哈希函数(hash function)用 key 定位到对应的桶。哈希函数的作用是将一个较大的输入空间映射到一个较小的输出空间。在哈希表中,输入空间是所有的 key,输出空间是所有桶(数组索引)。换句话说,输入一个 key,我们可以通过哈希函数得到该 key 在数组中的存储位置。
对于输入一个 key,哈希函数的计算过程分为以下两步:
- 通过某种哈希算法计算得到哈希值。
- 将哈希值对桶数量(数组长度)
capacity 取模,从而获取该 key 对应的数组索引 index。
| Java |
|---|
| index = hash(key) % capacity;
|
随后,我们可以利用 index 在哈希表中访问对应的桶,从而获取 value。
设数组长度 capacity = 100,哈希算法 hash(key) = key,则哈希函数为 key % 100。下图以 key 为学号和 value 为姓名的例子,展示了哈希函数的工作原理。
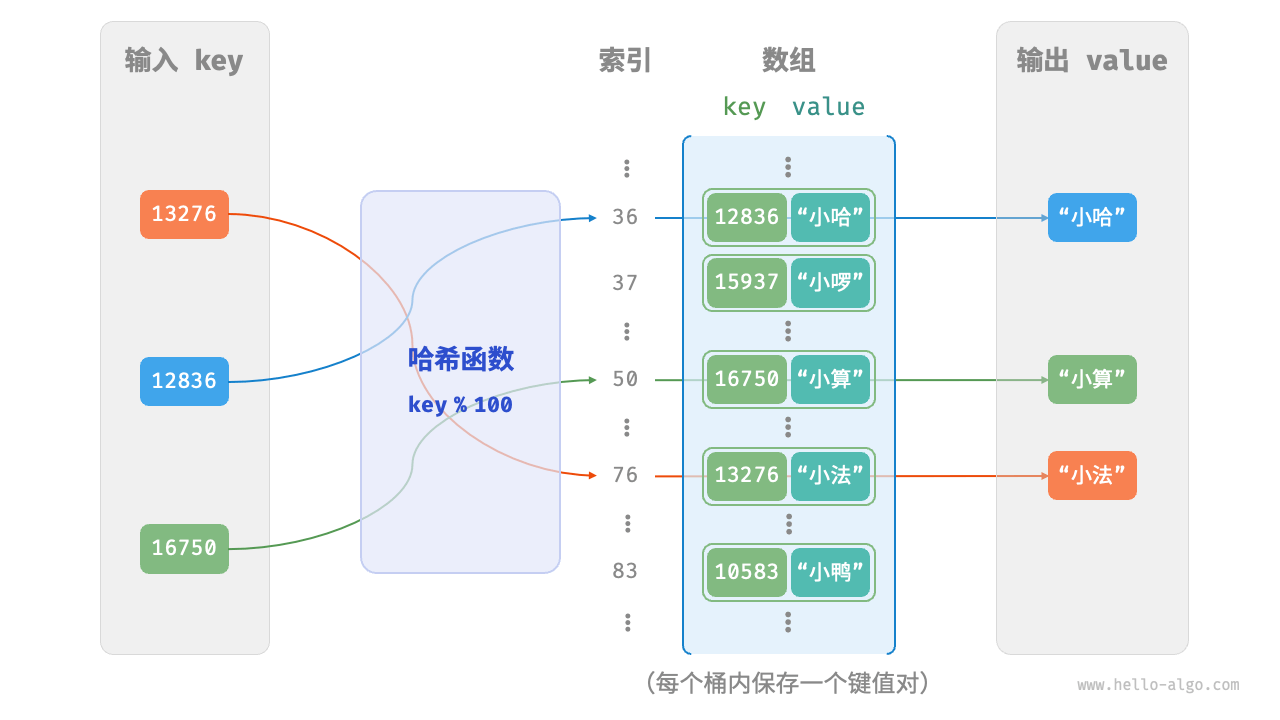
哈希冲突与性能
从本质上看,哈希函数的作用是将所有 key 构成的输入空间映射到数组所有索引构成的输出空间,而输入空间往往远大于输出空间。因此,理论上必然存在多个输入对应相同输出的情况。
例如,使用上述哈希函数,当输入的 key 后两位相同时,哈希函数的输出结果也相同。假设查询学号为 12836 和 20336 的两个学生时,我们得到:
| Text Only |
|---|
| 12836 % 100 = 36
20336 % 100 = 36
|
为了解决这个问题,HashMap 使用以下策略:
在 HashMap 中,哈希冲突发生时,会将多个键值对存储在同一个桶中。这会导致以下几点特性:
-
链表存储:
- 当多个键被映射到同一个桶时,
HashMap 会在该桶中使用链表来存储这些键值对。每个键值对由一个节点表示,节点中存储了键、值以及指向下一个节点的引用。
-
查找性能下降:
- 在查找过程中,如果发生哈希冲突,系统需要沿着链表遍历这些节点以找到对应的值。这意味着查找性能会受到影响,尤其是当桶中存储的键值对数量较多时,最坏情况下查找的时间复杂度将变为 O(n),其中 n 是冲突桶中键值对的数量。
- 在这种情况下,如果链表的长度大于阈值(默认是 8),
HashMap 会将链表转换为红黑树,从而提高查找效率。使用红黑树的查找时间复杂度为 O(log n),这在键值对数量较多时能显著提升性能。
-
容量与负载因子:
- 为了减少哈希冲突,
HashMap 的容量和负载因子(load factor)设置得当是很重要的。默认情况下,HashMap 的初始容量是 16,负载因子是 0.75。这意味着当填充的比例超过 75% 时,HashMap 会扩容并重新计算所有键值对的位置,从而降低冲突的概率。
1.7 HashMap的常见应用
1.7.1 字符频率统计
字典最常见的用途之一是频率统计,即用来统计数据出现的次数或频率。在需要处理大量数据时,字典可以通过键值对快速记录每个元素的出现次数。这样的操作时间复杂度为 O(1),因此相比于使用列表的 O(n) 查找,性能大幅提升。
常见应用:
- 查找出现次数最多的元素
- 判断数据集中是否存在重复元素
- 统计每个字符/数字/元素的频率
示例代码
| Java |
|---|
| import java.util.HashMap;
public class FrequencyCounter {
public static void main(String[] args) {
String input = "hello world";
HashMap<Character, Integer> frequencyMap = countFrequency(input);
// 打印每个字符的频率
for (Character key : frequencyMap.keySet()) {
System.out.println(key + ": " + frequencyMap.get(key));
}
}
// 统计字符频率
public static HashMap<Character, Integer> countFrequency(String s) {
HashMap<Character, Integer> freqMap = new HashMap<>();
for (char c : s.toCharArray()) {
// 如果字符已经在哈希表中,则增加计数
if (freqMap.containsKey(c)) {
freqMap.put(c, freqMap.get(c) + 1);
} else {
// 如果字符不在哈希表中,初始化计数为 1
freqMap.put(c, 1);
}
}
return freqMap;
}
}
|
1.7.2 快速查找
快速查找是通过哈希表实现的,它利用哈希函数的性质在常数时间内完成查找任务。其核心在于高效性——相比于列表遍历的 O(n)时间复杂度,字典通过哈希查找可以在 O(1) 时间内找到对应的值。快速查找并不关心具体的映射关系,而是着重强调查找速度的提升。
简单来说,快速查找是字典利用哈希表实现的高效查找操作,强调时间复杂度为 O(1),适用于在数据集中快速定位特定元素。
例如,通过给定学生学号,查找对应的学生姓名时,字典通过哈希表可以快速返回查询结果。
| Java |
|---|
| import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
// 创建 HashMap,存储学号和姓名
HashMap<Integer, String> students = new HashMap<>();
// 向 HashMap 添加键值对
students.put(1001, "Alice");
students.put(1002, "Bob");
students.put(1003, "Charlie");
// 根据学号快速查找对应的学生姓名
int studentId = 1002;
System.out.println(students.get(studentId)); // 输出:Bob
}
}
|
1.7.3 哈希映射
哈希映射是一个更广泛的概念,表示通过哈希函数将一个键(key)映射到一个值(value),这种键值对可以用于构建各种关系,不仅限于频率统计或快速查找。例如,将人名映射到学校,或者将学校映射到一个包含所有学生的人名列表,都是哈希映射的应用。哈希映射可以支持一对一、一对多等复杂的关系结构。
简单来说,哈希映射是广泛使用的映射机制,能够灵活实现键值对关系,应用于更多复杂场景,如一对一、一对多的映射。
一对一映射示例
| Java |
|---|
| import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
// 创建一个HashMap用于存储人名到学校的映射(人名 -> 学校)
HashMap<String, String> peopleToSchool = new HashMap<>();
// 添加一些键值对
peopleToSchool.put("Alice", "Harvard");
peopleToSchool.put("Bob", "MIT");
// 打印映射
System.out.println("Alice's school: " + peopleToSchool.get("Alice")); // 输出: Harvard
System.out.println("Bob's school: " + peopleToSchool.get("Bob")); // 输出: MIT
}
}
|
一对多映射示例
| Java |
|---|
| import java.util.HashMap;
import java.util.ArrayList;
import java.util.List;
public class HashMapOneToMany {
public static void main(String[] args) {
// 创建一个HashMap用于存储学校到学生列表的映射(学校 -> 学生列表)
HashMap<String, List<String>> schoolToPeople = new HashMap<>();
// 向Harvard学校添加学生
List<String> harvardStudents = new ArrayList<>();
harvardStudents.add("Alice");
harvardStudents.add("Charlie");
schoolToPeople.put("Harvard", harvardStudents);
// 向MIT学校添加学生
List<String> mitStudents = new ArrayList<>();
mitStudents.add("Bob");
schoolToPeople.put("MIT", mitStudents);
// 打印学校对应的学生列表
System.out.println("Students at Harvard: " + schoolToPeople.get("Harvard")); // 输出: [Alice, Charlie]
System.out.println("Students at MIT: " + schoolToPeople.get("MIT")); // 输出: [Bob]
}
}
|
说明:
- 一对一映射:
HashMap<String, String> 存储人名(键)与学校名称(值)的映射关系,每个键只能映射到一个值。
- 一对多映射:使用
HashMap<String, List<String>> 来实现学校名称(键)到学生列表(值)的映射,表示一个学校可以关联到多个学生。
2. 例题讲解和举一反三
2.1 频率统计与计数专题
2.1.1 例题讲解:LC242 有效的字母异位词
问题描述
描述:给定两个字符串s和t。
要求:判断t和s是否使用了相同的字符构成(字符出现的种类和数目都相同)。
思路分析
-
长度检查:
- 首先比较两个字符串的长度。如果长度不相等,立即返回
false。这是因为字母异位词必须具有相同数量的字符。
-
字符频率统计:
- 使用两个哈希表(
HashMap)分别统计两个字符串中每个字符的出现次数。哈希表的键为字符,值为该字符出现的次数。
-
遍历字符串:
- 遍历第一个字符串
s,对于每个字符,更新其在哈希表 countS 中的计数。
- 同时遍历第二个字符串
t,更新其在哈希表 countT 中的计数。
-
比较哈希表:
- 最后,通过比较两个哈希表是否相等来判断这两个字符串是否为有效的字母异位词。如果相等,返回
true;否则返回 false。
参考解答
| Java |
|---|
| import java.util.HashMap;
class Solution {
public boolean isAnagram(String s, String t) {
// 如果两个字符串长度不相同,直接返回 false
if (s.length() != t.length()) {
return false;
}
// 创建两个 HashMap 用于存储字符出现的频率
HashMap<Character, Integer> countS = new HashMap<>();
HashMap<Character, Integer> countT = new HashMap<>();
// 遍历字符串 s 和 t,统计每个字符的出现次数
for (int i = 0; i < s.length(); i++) {
countS.put(s.charAt(i), countS.getOrDefault(s.charAt(i), 0) + 1);
countT.put(t.charAt(i), countT.getOrDefault(t.charAt(i), 0) + 1);
}
// 比较两个 HashMap 是否相等
return countS.equals(countT);
}
}
|
2.1.2 举一反三:LC 387 字符串中的第一个唯一字符
问题描述
给定一个字符串 s,找到它的第一个不重复的字符,并返回它的索引。如果不存在这样的字符,则返回 -1。
思路分析
为了有效地解决这个问题,我们可以使用 HashMap 来记录每个字符出现的次数。这种方法分为两个步骤:
-
第一次遍历:统计字符出现次数
使用 HashMap 记录字符串中每个字符的出现次数。
-
第二次遍历:找到第一个不重复的字符
再次遍历字符串,检查每个字符的出现次数,找到第一个出现次数为 1 的字符,并返回其索引。
参考解答
| Java |
|---|
| import java.util.HashMap;
class Solution {
public int firstUniqChar(String s) {
HashMap<Character, Integer> count = new HashMap<>(); // 创建 HashMap 来存储字符计数
// 第一次遍历,统计每个字符的出现次数
for (int i = 0; i < s.length(); i++) {
char currentChar = s.charAt(i);
count.put(currentChar, count.getOrDefault(currentChar, 0) + 1);
}
// 第二次遍历,找到第一个不重复的字符
for (int i = 0; i < s.length(); i++) {
if (count.get(s.charAt(i)) == 1) { // 检查字符出现次数
return i; // 返回第一个不重复字符的索引
}
}
return -1; // 如果没有找到不重复字符,返回 -1
}
}
|
2.2 快速查找专题
2.2.1 例题讲解:LC1 两数之和
问题描述
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出和为目标值 target 的那两个整数,并返回它们的数组下标。假设每种输入只会对应一个答案,并且不能使用同一个元素两次。
思路分析
遍历数组,对于每一个数 nums[i]:
- 查找
HashMap 中是否存在 target - nums[i],如果存在,则输出该值对应的下标和当前数组的下标 i。
- 如果不存在,则将当前数
nums[i] 和它的下标 i 存入 HashMap 中。
参考解答:
| Java |
|---|
| import java.util.HashMap;
class Solution {
public int[] twoSum(int[] nums, int target) {
// 创建一个 HashMap 来存储数字及其对应的下标
HashMap<Integer, Integer> hashtable = new HashMap<>();
// 遍历数组
for (int i = 0; i < nums.length; i++) {
// 计算当前数字所需的另一个数字
int complement = target - nums[i];
// 检查 HashMap 中是否存在所需的数字
if (hashtable.containsKey(complement)) {
// 返回所需数字的下标和当前数字的下标
return new int[] { hashtable.get(complement), i };
}
// 将当前数字和它的下标存入 HashMap
hashtable.put(nums[i], i);
}
// 如果没有找到,返回空数组(根据题意,应该永远找到答案)
return new int[0];
}
}
|
2.2.2 举一反三:例题讲解:LC217 存在重复元素
问题描述
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。
思路分析
这道题目要求判断一个数组里有没有重复的数字。我们可以使用一个HashMap来存储每个数字是否已经出现过。当我们遍历数组时,每遇到一个数字,就检查它是否已经存在于HashMap中。如果已经存在,说明这个数字重复了,直接返回 true;如果没有,就把这个数字加到HashMap里,继续检查下一个数字。遍历完数组后,如果没有找到任何重复数字,就返回 false。
这样做的好处是每个数字只会检查一次,并且查找和存储数字的操作也很快,因此整个过程很高效。
提示
HashMap可以用来快速存储和查找数字,这样可以避免重复的数字。
参考解答
| Java |
|---|
| import java.util.HashMap;
class Solution {
public boolean containsDuplicate(int[] nums) {
// 创建 HashMap 来存储数字
HashMap<Integer, Boolean> map = new HashMap<>();
// 遍历数组
for (int num : nums) {
// 如果 HashMap 已经包含当前数字,说明有重复,返回 true
if (map.containsKey(num)) {
return true;
}
// 否则,将当前数字添加到 HashMap 中,标记为已出现
map.put(num, true);
}
// 如果遍历结束没有发现重复元素,返回 false
return false;
}
}
|
2.3 哈希映射专题
2.3.1 LC 697 数组的度
问题描述
给定一个非空且只包含非负数的整数数组 nums,数组的 度 的定义是指数组里任一元素出现频数的最大值。你的任务是在 nums 中找到与 nums 拥有相同大小的度的最短连续子数组,返回其长度。
思路分析
记原数组中出现次数最多的数为 x,那么和原数组的度相同的最短连续子数组,必然包含了原数组中的全部 x,且两端恰为 x 第一次出现和最后一次出现的位置。
为了找到这个子数组,我们需要统计每一个数出现的次数,同时还需要统计每一个数第一次出现和最后一次出现的位置。我们使用一个哈希表来实现这个功能,每一个数映射到一个长度为 3 的数组,数组中的三个元素分别代表这个数出现的次数、这个数在原数组中第一次出现的位置和这个数在原数组中最后一次出现的位置。当我们记录完所有信息后,我们需要遍历该哈希表,找到元素出现次数最多,且前后位置差最小的数。
提示
- 先记录每个元素出现的次数,第一次和最后一次的索引。
- 找到数组的度和最短子数组的长度。
参考解答
| Java |
|---|
| import java.util.HashMap;
import java.util.Map;
class Solution {
public int findShortestSubArray(int[] nums) {
// 使用哈希表存储每个数的出现次数和第一次、最后一次出现的位置
Map<Integer, int[]> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
if (map.containsKey(nums[i])) {
map.get(nums[i])[0]++; // 增加出现次数
map.get(nums[i])[2] = i; // 更新最后一次出现的位置
} else {
// 初始化:出现次数、第一次和最后一次出现的位置
map.put(nums[i], new int[]{1, i, i});
}
}
int maxNum = 0; // 记录出现次数最多的数的次数
int minLen = Integer.MAX_VALUE; // 记录最短子数组的长度
// 遍历哈希表
for (int[] value : map.values()) {
int count = value[0]; // 出现次数
int left = value[1]; // 第一次出现的位置
int right = value[2]; // 最后一次出现的位置
// 更新 maxNum 和 minLen
if (maxNum < count) {
maxNum = count;
minLen = right - left + 1; // 更新最短子数组长度
} else if (maxNum == count) {
minLen = Math.min(minLen, right - left + 1); // 更新最短子数组长度
}
}
return minLen; // 返回最短子数组的长度
}
}
|
解题过程:
- 初始化哈希表
map。
- 遍历数组
nums,记录每个元素的出现次数、第一次出现的索引和最后一次出现的索引。
- 遍历哈希表的值,提取每个数字的出现次数、第一次和最后一次出现的位置。
maxNum 记录当前出现次数最多的值(即数组的度)。minLen 记录具有相同度的子数组的最短长度。- 如果当前元素的出现次数大于
maxNum,更新 maxNum 和最短子数组长度 minLen。
- 如果出现次数相同,检查当前子数组是否比之前的短,并更新
minLen。
2.3.2 举一反三:LC 205 同构字符串
问题描述
给定两个字符串 s 和 t ,判断它们是否是同构的。
如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。
每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。
思路分析
根据题目意思,字符串 s 和 t 每个位置上的字符是一一对应的。s 的每个字符都与 t 对应位置上的字符对应。可以考虑用哈希表来存储 s[i]:t[i] 的对应关系。但是这样只能保证对应位置上的字符是对应的,但不能保证是唯一对应的。因此,还需要另一个哈希表来存储 t[i]:s[i] 的对应关系,以判断是否是唯一对应的。
提示
属于建立映射,通过创建字典建立字母和出现字母的映射关系。
参考解答
| Java |
|---|
| import java.util.HashMap;
class Solution {
public boolean isIsomorphic(String s, String t) {
// 创建两个哈希表来存储映射关系
HashMap<Character, Character> sToT = new HashMap<>();
HashMap<Character, Character> tToS = new HashMap<>();
// 遍历字符串 s 和 t
for (int i = 0; i < s.length(); i++) {
char sChar = s.charAt(i);
char tChar = t.charAt(i);
// 检查 s 中的字符到 t 的映射
if (sToT.containsKey(sChar)) {
// 如果已经存在映射但与当前字符不一致,返回 false
if (sToT.get(sChar) != tChar) {
return false;
}
} else {
// 添加映射
sToT.put(sChar, tChar);
}
// 检查 t 中的字符到 s 的映射
if (tToS.containsKey(tChar)) {
// 如果已经存在映射但与当前字符不一致,返回 false
if (tToS.get(tChar) != sChar) {
return false;
}
} else {
// 添加映射
tToS.put(tChar, sChar);
}
}
return true; // 如果没有冲突,返回 true
}
}
|
解题过程:
- 初始化两个哈希表
sToT 和 tToS,用于存储字符之间的映射关系。
- 遍历字符串
s 和 t 的每个字符。
- 对于每个字符,检查是否已存在映射关系:
- 如果已存在且映射关系不一致,返回
false。
- 如果不存在映射关系,则添加新的映射。
- 如果遍历结束后没有返回
false,则说明字符串是同构的,返回 true。
2.3.3 举一反三:LC219 存在重复元素II
问题描述
给定一个整数数组 nums 和一个整数 k,判断数组中是否存在两个 不同的索引 i 和 j,使得 nums[i] == nums[j] 且 abs(i - j) <= k。如果存在,返回 true;否则,返回 false。
思路分析
我们需要判断一个整数数组 nums 中是否存在两个不同的索引 i 和 j,使得 nums[i] == nums[j] 并且 abs(i - j) <= k。换句话说,我们要检查是否有重复的元素,并且这些元素之间的索引差不超过 k。
- 使用 HashMap 存储索引:
-
我们使用一个 HashMap(或字典)来存储每个元素最后一次出现的位置。这是因为我们只需要关心每个元素的最后一次出现的索引,以便快速判断它与当前索引的差值。
-
遍历数组:
-
遍历数组 nums,对于每一个元素 num:
- 首先检查该元素是否已存在于 HashMap 中:
- 如果存在,说明我们之前已经遇到过这个元素。此时,计算当前索引
i 和该元素上次出现索引之间的差值。
- 如果这个差值小于等于
k,则返回 true,表示找到了符合条件的重复元素。
- 如果不存在,或差值不满足条件,则更新 HashMap,将该元素及其当前索引存入。
-
遍历结束:
- 如果遍历完数组都没有找到满足条件的重复元素,返回
false。
参考解答
| Java |
|---|
| import java.util.HashMap;
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
HashMap<Integer, Integer> pos = new HashMap<>(); // 创建一个 HashMap 存储数字及其最后出现的位置
for (int i = 0; i < nums.length; i++) { // 遍历数组
if (pos.containsKey(nums[i]) && i - pos.get(nums[i]) <= k) { // 检查是否存在重复且满足索引差
return true; // 找到满足条件的重复元素
}
pos.put(nums[i], i); // 更新当前数字的位置
}
return false; // 没有找到符合条件的重复元素
}
}
|
3. 课后练习
频率统计
| 题目编号 |
题目名称 |
题目描述 |
| LC 451 |
根据字符出现频率排序 |
给定一个字符串,请将字符按出现频率排序。 |
| LC 692 |
前K个高频单词 |
给定一个单词列表,返回前 K 个出现频率最高的单词。 |
| LC 347 |
前K个高频元素 |
给定一个整数数组,返回出现频率前 K 高的元素 |
| LC 554 |
砌墙 |
计算通过一堵墙的垂直线段穿过的砖块数量最少的地方。 |
| LC 2085 |
统计出现过一次的公共字符串 |
返回在两个字符串数组中都恰好出现一次的字符串的数目。 |
快速查找
| 题目编号 |
题目名称 |
题目描述 |
| LC 594 |
最长和谐子序列 |
找到和谐子序列的最长长度,最大值和最小值相差为1。 |
| LC 525 |
连续数组 |
给定一个二进制数组,找到长度相同的0和1的最长子数组。 |
| LC 49 |
字母异位词分组 |
给定一个字符串数组,将字母异位词组合在一起。 |
| LC 169 |
多数元素 |
给定一个大小为n的数组nums,返回其中的多数元素。 |
| LC 409 |
最长回文串 |
给定一个字符串,返回其中可以构成的最长回文串的长度。 |
哈希映射
| 题目编号 |
题目名称 |
题目描述 |
| LC 290 |
单词规律 |
给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。 |
| LC 560 |
和为K的子数组 |
找出数组中和为 k 的连续子数组的个数。 |
| LC 249 |
移位字符串分组 |
给定一个包含仅小写字母字符串的列表,将该列表中所有满足 “移位” 操作规律的组合进行分组并返回。 |
| LC 953 |
验证外星语词典 |
给定一个外星词典的顺序表,判断一组单词是否按照这个外星词典的顺序排列。 |
| LC 12 |
整数转罗马数字 |
给定一个整数,将其转换为罗马数字。 |